Whisper on Azure: what Microsoft actually sells, and where it fits now
How Microsoft packages OpenAI's Whisper across Azure OpenAI and Azure Speech: limits, pricing signals, benchmarks, security, and where it fits in 2026.
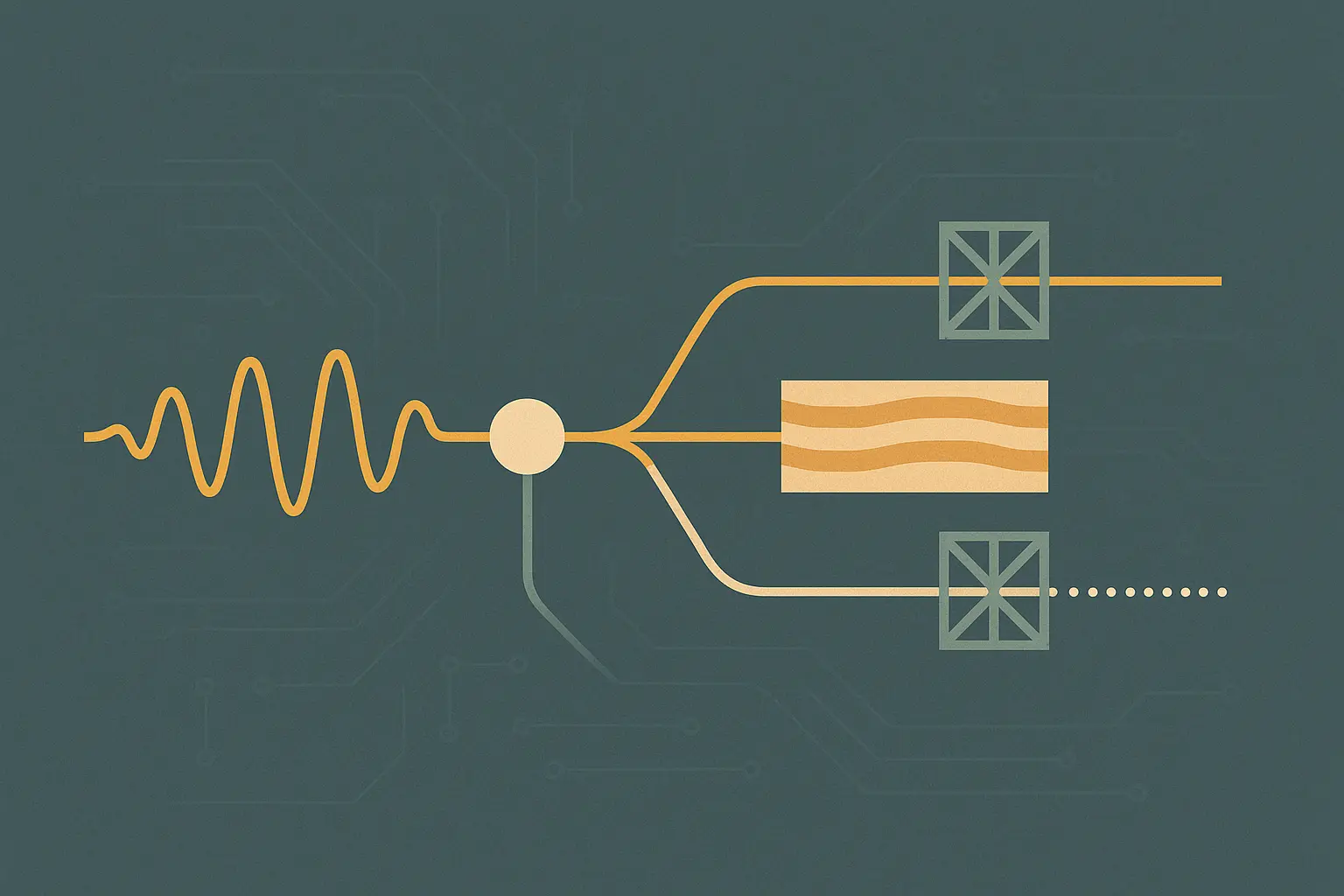
Microsoft's "Whisper on Azure" is not a single product. It is a set of Azure delivery paths wrapped around OpenAI's Whisper speech model, and if you evaluate it as one thing you will get confused fast. The two primary surfaces are a managed Azure OpenAI model endpoint named whisper for file-based speech-to-text and speech-to-English translation, and Azure Speech batch transcription support for Whisper, which adds enterprise transcription features like larger files, asynchronous batch operation, speaker diarization, and word-level timestamps. Microsoft's newer audio roadmap now layers successors on top of that base: GPT-4o transcription models and GPT Realtime Whisper for low-latency streaming transcription.
The core Azure OpenAI Whisper endpoint is deliberately simple. One managed Azure model ID, whisper, exposed through /audio/transcriptions and /audio/translations, with a documented maximum request size of 25 MB. Microsoft does not publicly expose model-size choices such as tiny, base, small, medium, or large on that managed endpoint. That matters because the open-source Whisper ecosystem does expose six model sizes through OpenAI's repository, and Azure's broader model catalog separately lists openai-whisper-large-v3 as a distinct managed-compute catalog model. Same model family, three very different product surfaces.
Azure Speech's Whisper path is the more enterprise-specialized option for prerecorded audio at scale. Microsoft's launch and GA materials say it supports files up to 1 GB, up to 1,000 files in a single batch request, speaker diarization, and word-level timestamps. Azure OpenAI Whisper, by contrast, is positioned for smaller prerecorded files and time-sensitive workloads, while Microsoft steers live and ultra-low-latency use cases toward GPT Realtime Whisper or Azure Speech real-time and fast transcription.
The release history is short at the top level. OpenAI shipped Whisper in September 2022. Microsoft brought it to Azure in public preview on September 15, 2023, then made it generally available in Azure OpenAI and Azure Speech on March 13, 2024. Later updates repositioned the managed whisper endpoint inside a wider Azure speech stack rather than changing it: Confidential Inferencing preview arrived in September 2024, GPT-4o transcription models arrived in April 2025, and GPT Realtime Whisper documentation appeared in May 2026 to cover low-latency streaming transcription.
Microsoft's motivation was spelled out in its own announcements: enterprises wanted Whisper's multilingual robustness, but with Azure's security, governance, regional controls, and integration into existing speech workflows. That is why Azure offered Whisper through both Azure OpenAI and Azure Speech from day one. The tradeoff is equally plain. Azure's Whisper offer is strong for general-purpose multilingual ASR under enterprise controls, and weaker than some competing stacks if you want customer-visible model-size selection, deep public benchmark transparency, or fully documented on-prem Whisper packaging.
Reception splits along the same line. Enterprise adoption looks healthy; Microsoft says "thousands of customers" were already using Whisper on Azure by GA. Technical scrutiny is more mixed. Independent studies generally confirm that Whisper remains a strong multilingual baseline and often beats older cloud ASR systems on difficult data, but they also flag hallucinations and domain sensitivity. Microsoft does not publish Whisper-specific p50/p95 latency or WER targets, so any accuracy or speed claim beyond product positioning still needs workload-specific testing.
Three surfaces, one model name
Azure currently exposes Whisper in three meaningfully different ways, and the distinctions matter more than the model name. The managed Azure OpenAI endpoint called whisper is the closest equivalent to the OpenAI-hosted Whisper API. Azure Speech uses Whisper through its batch transcription API and builds transcription-specific capabilities around it. And Azure's model catalog contains openai-whisper-large-v3 as an open-model-style catalog entry on managed compute, related to the Whisper family but not the same product as Azure OpenAI's managed whisper endpoint.
| Surface | What Azure exposes | Model-size choice exposed to customer | Technical specialization | Key documented limits and caveats | Sources |
|---|---|---|---|---|---|
| Azure OpenAI Whisper | Model ID whisper, version 001, via /audio/transcriptions and /audio/translations | No public size choice on the managed endpoint | File-based STT and speech translation into English; managed Azure OpenAI experience | 25 MB max audio request; prerecorded/file-based rather than streaming; Microsoft publicly documents one managed SKU rather than tiny/base/small/medium/large choices | |
| Azure Speech with Whisper | Whisper selectable through Azure Speech batch transcription | No public size choice in the batch API docs | Large-volume prerecorded transcription with async processing, diarization, and timestamps | Up to 1 GB per file, up to 1,000 files per request; intended for batch, not live streaming | |
| Azure model catalog openai-whisper-large-v3 | Separate catalog model on managed compute | Yes, implicitly, because the catalog entry is specifically large-v3 | For teams that want a specific open Whisper checkpoint on Azure infrastructure rather than the Azure OpenAI managed API SKU | Distinct from Azure OpenAI whisper; listed as 1.55B parameters and generally available in catalog |
Microsoft's own portfolio guidance is now explicit about role separation. Azure OpenAI audio models are for scenarios that combine speech with language reasoning or flexible prompt-based control. Azure Speech is for high-volume real-time or batch transcription, diarization, custom speech models, and deployments that may require container or sovereign-cloud options. In practice, Azure OpenAI Whisper is the lightweight managed transcription entry point and Azure Speech is the operationally specialized speech platform.

Capabilities, languages, APIs, and limits
Microsoft's launch and GA materials describe Whisper on Azure as supporting transcription in 57 languages and translation from those languages into English. Azure OpenAI's REST reference defines two core operations: /audio/transcriptions, which transcribes into the input language, and /audio/translations, which transcribes and translates into English text. The REST API also documents a language hint that improves both accuracy and latency.
For Azure OpenAI, Microsoft documents the managed whisper model as a general-purpose speech recognition model with a 25 MB maximum request size. The quickstart and samples cover REST/cURL, Python, JavaScript/TypeScript via the OpenAI client library with AzureOpenAI, and PowerShell. The quickstart lists common input formats including mp3, mp4, mpeg, mpga, m4a, wav, and webm.
For Azure Speech, the Whisper support is built around batch transcription. The preview and GA announcements say Azure Speech adds asynchronous processing, speaker diarization, word-level timestamps, and much larger file and batch capacity. Microsoft's broader speech stack now also includes fast transcription, which "returns results synchronously and faster than real-time," and LLM Speech, which supports multilingual transcription and translation, diarization, and prompt-tuning capabilities at up to 500 MB and under 5 hours per file.
Microsoft does not publish a Whisper-specific latency SLA, a p50/p95 latency table, or a public Azure-hosted WER chart for the managed whisper endpoint. It uses positioning language instead: Azure OpenAI Whisper for smaller files and time-sensitive work, Azure Speech fast transcription as explicitly faster than real-time for prerecorded audio, GPT Realtime Whisper for low-latency streaming captions and monitoring. Read between the lines and Azure itself treats Whisper as the base model lane, not the final answer for every latency-sensitive speech workload.
Pricing is consumption-based, and the exact current numbers are harder to pin down than the feature docs. The official Azure Speech pricing page says speech-to-text hours are measured by hours of audio sent and billed in one-second increments, with separate SKUs for standard transcription, fast transcription, batch transcription, and LLM Speech. Microsoft moderators publicly cited Azure OpenAI Whisper pricing at $0.36 per audio hour in the US region in late 2023, but the primary Azure pricing pages are dynamically rendered and do not expose a stable current Whisper line item in retrieved HTML. The honest summary: usage-based audio billing, region-sensitive pricing, and you should verify the pricing calculator before budgeting.
The most concrete numeric specialization Microsoft publishes is input-size headroom across the transcription paths: 25 MB for Azure OpenAI whisper, under 500 MB for Azure Speech LLM Speech, and up to 1 GB for Azure Speech Whisper batch transcription. That single spread tells you most of what you need to know about which lane handles which job.
Release history and timeline
The Azure Whisper story is less about frequent checkpoint swaps and more about delivery-path expansion. The documented milestones trace a classic enterprise productization arc: OpenAI created Whisper, Microsoft brought it into Azure in preview and then GA, Azure Speech hardened the batch route, Azure Confidential Computing added privacy-oriented deployment options, and later Azure audio releases shifted the lowest-latency recommendation toward GPT-4o and realtime speech models rather than the original managed Whisper endpoint.
| Date | Milestone | What changed | Why Microsoft updated it | Sources |
|---|---|---|---|---|
| September 21, 2022 | OpenAI releases Whisper | Whisper launches as an ASR system trained on 680,000 hours of multilingual/multitask audio data | Established the upstream model that Azure later commercialized | |
| September 15, 2023 | Azure public preview | Microsoft announces Whisper preview in both Azure OpenAI Service and Azure AI Speech | To bring OpenAI Whisper into Azure with enterprise controls and two usage paths: simple API and batch speech pipeline | |
| September 2023 | Azure Speech REST API v3.2 preview | Azure Speech v3.2 preview adds the API path that supports Whisper for batch transcription | To enable Whisper inside the existing Speech batch ecosystem | |
| March 13, 2024 | General availability | Whisper becomes GA in Azure OpenAI and Azure Speech | To move Whisper into production workloads under Azure's enterprise-readiness positioning | |
| June 2024 | Azure Speech REST API v3.2 GA | Speech batch API version supporting Whisper goes GA | To stabilize the Azure Speech integration path for production batch transcription | |
| September 24, 2024 | Confidential Inferencing preview | Microsoft announces confidential inferencing preview for Azure OpenAI Whisper | To support verifiable end-to-end privacy for regulated workloads | |
| April 2025 | GPT-4o transcription models released on Azure | gpt-4o-transcribe and gpt-4o-mini-transcribe arrive in Azure OpenAI | To improve accuracy, flexibility, and voice-first application support beyond classic Whisper | |
| May 2026 | GPT Realtime Whisper documentation appears | Azure publishes GPT Realtime Whisper concept docs | To cover low-latency streaming transcription for captions, monitoring, and archival workflows, a gap in the original file-based Whisper API |
The most recent Whisper-family update in these sources is the May 2026 publication of GPT Realtime Whisper documentation, and Microsoft's wording gives away the reason: low-latency, stream-based transcription for live captions and monitoring. Azure's latest Whisper-related evolution is not a bigger classic Whisper. It is a more specialized realtime transcription lane.

Where the model came from and what Microsoft added
The underlying model was created by OpenAI, not Microsoft. OpenAI's Whisper paper is authored by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever, and the model was trained on 680,000 hours of multilingual and multitask supervised audio data from the web. OpenAI positioned Whisper as robust to accents, background noise, and technical language, with multilingual transcription and translation into English.
Microsoft's role was productization: hosting, governance, and service integration. Public Azure messaging places Whisper under the Azure AI, Azure OpenAI, and Azure Speech umbrella. The public preview announcement came from Microsoft's Heiko Rausch on the Azure AI services blog, and the GA announcement from Marco Casalaina, Vice President of Products for Azure AI. Microsoft does not publish a named "Azure Whisper engineering team" roster in the retrieved sources, so anything deeper than that would be guesswork.
The relationship to other Whisper projects deserves care. Azure OpenAI's managed whisper endpoint is not the open-source openai/whisper repository, which exposes model sizes tiny, base, small, medium, large, and turbo, with explicit parameter counts and hardware tradeoffs. Azure also separately catalogs openai-whisper-large-v3 on managed compute, another sign that Microsoft distinguishes between managed Azure OpenAI Whisper as a turnkey service and specific open Whisper checkpoints available elsewhere in the Foundry ecosystem.
One clarification worth making because the question comes up: there is no meaningful public evidence that Meta played any role in Azure's Whisper offer. Meta models such as MMS belong to a separate multilingual speech line, and community benchmark commentary notes that MMS-style models may support many more languages but often trail more specialized encoders in accuracy. Azure Whisper is an OpenAI-derived offer, full stop.
Microsoft's stated motivation was enterprise-facing from the start. Its GA announcement says enterprises struggle to analyze voice interactions across many languages while preserving security and privacy guardrails, and frames Whisper on Azure as giving customers a choice between Azure OpenAI and Azure Speech for call-center analytics, captions and accessibility, and mining audio and video for insights. The later architecture guidance sharpened that: Azure OpenAI for flexible AI-native audio workflows, Azure Speech for volume, predictability, customization, diarization, and deployment constraints.
What the benchmarks and the market actually say
Microsoft's strongest public adoption signal is scale language rather than audited usage metrics. At GA, the company said "thousands of customers" had already used the Whisper API in Azure across healthcare, education, finance, manufacturing, media, and agriculture, and highlighted accessibility captions, call-center analytics, and insight extraction from audio and video as prominent use cases. Meaningful, but Microsoft did not publish customer counts by segment, revenue contribution, or benchmarked throughput statistics.
The featured customer proof point at GA was Lightbulb.AI, which used Whisper in Azure OpenAI Service for call-center workflows. Lightbulb's published quote claimed its product was "500X more scalable, 90X faster, and 20X more cost-effective than manual call reviews." Those are customer-reported figures, not third-party audited benchmarks, but they show the ROI narrative Microsoft used to frame Whisper on Azure.
Independent benchmark evidence is more useful. In the PennSound evaluation, researchers tested AWS, Azure, Google, IBM, Rev.ai, Whisper, and Whisper.cpp on nearly 10 hours of varied archival audio. Their conclusion: Rev.ai was the top performer overall and Whisper was the top open-source performer "as long as hallucinations were avoided," with relatively slim WER and diarization gaps across systems. A strong result for the Whisper family, not a dominant one, and it specifically flags hallucination behavior as a practical deployment concern.
A 2024 child-speech study is especially revealing because it puts Microsoft Azure Speech, Google Cloud Speech-to-Text, and multiple Whisper sizes against genuinely difficult speech. On that dataset, the best Whisper model achieved a WER of 21.3%, versus 30.3% for Azure and 49.0% for Google. The same study found that local Whisper variants could beat cloud systems on responsiveness in some setups, though that partly reflects hardware choice and network overhead rather than pure model quality. The lesson: Whisper can materially outperform traditional cloud ASR on hard multilingual, noisy, or atypical speech, but not uniformly across all tasks.
Another large comparative study on ASR accuracy found that Microsoft and Whisper tended to report lower confidence than measured accuracy, while some rivals appeared overconfident. That is not a quality judgment by itself, but it matters for downstream systems that use confidence thresholds for routing or human review. The same study observed that higher accuracy did not necessarily correlate with shorter processing time.
The main public criticism of Whisper has been hallucination risk. The Associated Press reported in 2024 that researchers and practitioners had seen Whisper invent words, passages, or medically consequential details that were never spoken. Azure's offering is built on the Whisper family, so that criticism travels with it, especially into healthcare, legal, and compliance workflows. Microsoft's own later audio roadmap, with improved hallucination-handling claims for newer transcription models, quietly concedes that robustness under silence and noise became an important post-Whisper improvement area.
The market impact inside Azure comes down to this: Whisper established Azure as a serious multilingual ASR option tied to OpenAI's model brand, but the subsequent speech roadmap shows Whisper became the foundation of the portfolio rather than its frontier. GPT-4o transcription models, LLM Speech, and GPT Realtime Whisper are where Microsoft now appears to be investing its latest speech differentiation.

Integration, security, privacy, and compliance
Microsoft's architecture guidance is unusually practical about which service to pick. Use Azure OpenAI audio models when the speech workload is part of a larger reasoning, summarization, or generation workflow, when you want flexible prompt-based control, or when you are already in the Azure OpenAI stack. Use Azure Speech when you need predictable high-volume transcription, diarization, custom speech models, custom vocabulary, or on-prem, container, and sovereign-cloud deployment options. That makes Azure Whisper highly relevant, and not always the recommended first choice even inside Azure.
For Whisper use cases specifically, Microsoft's materials point to small prerecorded audio files, translation of non-English speech into English, call-center post-call analysis, accessibility captions, and mining large audio and video corpora for searchable text and downstream insight extraction. Azure Speech with Whisper is the better fit when the requirement is many files, large files, batch, speakers, and timestamps. Azure OpenAI Whisper fits when the requirement is simple managed Whisper access under Azure controls.
Security and data handling are the real differentiators versus direct third-party hosting. Microsoft states that customer data, prompts, and completions are not available to other customers, not available to OpenAI or other model providers, not used to improve Microsoft or third-party products or services without explicit permission, and not used to train foundation models without customer permission or instruction. Prompts and responses are processed within the customer-specified geography unless the customer uses Global or DataZone deployment types. Stored data is encrypted at rest with AES-256 by default, with customer-managed keys available for supported scenarios.
Microsoft's Transparency Note adds that Azure OpenAI wraps OpenAI models inside Microsoft-managed guardrails and abuse-detection systems. That does not remove model limitations, but it is part of the enterprise-control layer Azure is selling around Whisper. For workloads that need stronger runtime privacy guarantees, Microsoft announced confidential inferencing preview for Azure OpenAI Whisper in late 2024, targeting end-to-end privacy in regulated industries.
On compliance, the accurate framing is that Azure Whisper inherits the broader Microsoft Azure compliance program rather than carrying a separately branded compliance regime. Microsoft says Azure has more than 100 compliance offerings and points to third-party reports and certifications such as ISO 27001, SOC 2, FedRAMP, and HITRUST across the platform. Microsoft also states that Azure supports customers subject to HIPAA and that Azure and Azure Government align with the NIST Cybersecurity Framework and are certified under ISO/IEC 27001. For actual regulated deployments, teams still need to validate service-specific scope in the Service Trust Portal and their contractual setup.
How it stacks up against the field
The competitive reality is that Azure Whisper wins on enterprise packaging and ecosystem fit, not public benchmark dominance. A team that wants a secure, governed, Azure-native way to use Whisper alongside adjacent services will find Azure strong. A team that wants deterministic speech-specific controls will often find Azure Speech beats Azure OpenAI Whisper inside Microsoft's own portfolio. And a team that wants the newest cloud ASR features in purely speech-centric stacks still has credible alternatives in Google Cloud Speech-to-Text, Amazon Transcribe, and the newer LLM-ASR vendors.
| Offering | Core lane | Languages stated publicly | Streaming / real-time | Diarization | Custom adaptation or tuning | On-prem / container path | Best fit | Sources |
|---|---|---|---|---|---|---|---|---|
| Azure OpenAI Whisper | Managed file-based transcription and speech-to-English translation | 57 at launch/GA messaging | Not for the core whisper lane; Microsoft now points low-latency streaming to GPT Realtime Whisper instead | Not documented for core whisper endpoint | No public customer-visible tuning flow documented for the core managed Azure OpenAI whisper SKU | No first-party Whisper container documented in retrieved sources | Small prerecorded multilingual files inside Azure OpenAI workflows | |
| Azure Speech with Whisper | Batch transcription using Whisper | Whisper multilingual plus translation to English | Batch only | Yes | For domain tuning, Microsoft generally steers customers to Azure Speech custom speech features rather than the basic Whisper batch lane | Azure Speech as a service supports containers more broadly, but Whisper-specific container packaging is not documented in the retrieved sources | Large prerecorded files, batch jobs, call recordings, post-call analytics | |
| Azure Speech native STT / fast / LLM Speech | Speech-specialized platform | Broad locale matrix | Yes | Yes | Yes | Yes | Deterministic enterprise STT, custom vocabulary/acoustics, regulated deployment constraints | |
| Google Cloud Speech-to-Text / Chirp | Managed cloud STT | 85+ languages and variants | Yes | Yes | Yes, model adaptation | Not documented in retrieved sources | Multilingual cloud STT with strong adaptation support | |
| Amazon Transcribe | Managed cloud STT | Broad supported-language matrix | Yes | Yes | Yes, custom vocabulary and custom language models | Not documented in retrieved sources | AWS-native batch and streaming transcription, especially call analytics workflows |
The buyer's readout falls out of that table. If the requirement is Whisper specifically, on Azure, with enterprise controls, Azure OpenAI Whisper is the direct answer. If the requirement is the best operational transcription service on Azure, Azure Speech is often the better answer. If the requirement is the lowest-latency live transcription, Microsoft's own newest guidance points away from classic Whisper toward GPT Realtime Whisper and other newer speech models. And if the requirement is classical cloud ASR with mature speech-specific adaptation knobs, Google and AWS remain very credible comparators.
What Microsoft still does not disclose
A few important details remain publicly incomplete, and they are worth knowing before you sign anything.
Microsoft does not clearly disclose the exact underlying checkpoint or parameter count behind the managed Azure OpenAI whisper SKU. Public documentation exposes only the managed model ID whisper and version 001.
There is no Whisper-specific public p50/p95 latency table or Azure-hosted WER benchmark sheet. Buyers need their own workload tests, full stop.
Current exact Whisper pricing is region-sensitive and not consistently visible in retrieved official HTML. The clearest public numeric reference is a Microsoft moderator citing $0.36 per audio hour in the US region in late 2023, and that should not be treated as a guaranteed current price.
Azure Speech broadly supports containers and on-prem deployment options, but the retrieved first-party documentation does not specifically package the Whisper batch route itself as an on-prem or containerized Whisper product.
Where to start reading
The most useful primary sources, if you want to go deeper:
The Microsoft Azure Blog post "Accelerate your productivity with the Whisper model in Azure AI now generally available" is the clearest GA-era product-positioning document and the best source for Microsoft's adoption claims and the Azure OpenAI versus Azure Speech split.
The Microsoft Tech Community post "Announcing the Preview of OpenAI Whisper in Azure OpenAI service and Azure AI Speech" is the best source for the initial Azure release date and the original two-path architecture.
Microsoft Learn's Azure OpenAI Whisper quickstart and REST reference are the best sources for the model ID, endpoints, API behavior, and request semantics.
Microsoft Learn's Azure Speech Whisper overview, release notes, architecture guidance, and quotas are the best sources for Azure Speech batch support, fast transcription, custom speech positioning, and on-prem and container guidance.
The OpenAI paper and the Whisper repo are the best sources for original model lineage, authorship, training data scale, and the open-source size variants.
Sources
Foundry Models sold by Azure, Microsoft Foundry, Microsoft Learn https://learn.microsoft.com/en-us/azure/foundry/foundry-models/concepts/models-sold-directly-by-azure
Announcing the Preview of OpenAI Whisper in Azure OpenAI service and Azure AI Speech, Microsoft Community Hub https://techcommunity.microsoft.com/t5/ai-azure-ai-services-blog/announcing-the-preview-of-openai-whisper-in-azure-openai-service/ba-p/3928388
Introducing Whisper, OpenAI https://openai.com/index/whisper/
Accelerate your productivity with the Whisper model in Azure AI now generally available, Microsoft Azure Blog https://azure.microsoft.com/en-us/blog/accelerate-your-productivity-with-the-whisper-model-in-azure-ai-now-generally-available/
AI Model Catalog, Microsoft Foundry Models (whisper) https://ai.azure.com/catalog/models/whisper
AI Model Catalog, Microsoft Foundry Models (openai-whisper-large-v3) https://ai.azure.com/catalog/models/openai-whisper-large-v3
Choose an Azure Speech Recognition and Generation Technology, Azure Architecture Center, Microsoft Learn https://learn.microsoft.com/en-us/azure/architecture/data-guide/ai-services/speech-recognition-generation
Pricing, Azure Speech in Foundry Tools, Microsoft Azure https://azure.microsoft.com/ja-jp/pricing/details/speech/
What's new, Speech service, Foundry Tools, Microsoft Learn https://learn.microsoft.com/en-us/azure/ai-services/speech-service/releasenotes
Microsoft Trustworthy AI: Unlocking human potential starts with trust, Microsoft Blog https://blogs.microsoft.com/blog/2024/09/24/microsoft-trustworthy-ai-unlocking-human-potential-starts-with-trust/
What's new in Azure OpenAI in Microsoft Foundry Models (classic), Microsoft Learn https://learn.microsoft.com/en-us/azure/foundry-classic/openai/whats-new
Robust Speech Recognition via Large-Scale Weak Supervision, arXiv https://arxiv.org/abs/2212.04356
GitHub, openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision https://github.com/openai/whisper
Open ASR Leaderboard, huggingface/blog, GitHub https://github.com/huggingface/blog/blob/main/open-asr-leaderboard.md
Evaluating Speech-to-Text Systems with PennSound, arXiv https://arxiv.org/html/2504.05702v1
Child Speech Recognition in Human-Robot Interaction: Problem Solved?, arXiv https://arxiv.org/html/2404.17394v2
Measuring the Accuracy of Automatic Speech Recognition Solutions, arXiv https://arxiv.org/html/2408.16287v1
Researchers say an AI-powered transcription tool used in hospitals invents things no one ever said, Associated Press https://apnews.com/article/90020cdf5fa16c79ca2e5b6c4c9bbb14
Data, privacy, and security for Foundry Models sold by Azure in Microsoft Foundry, Microsoft Learn https://learn.microsoft.com/en-us/azure/foundry/responsible-ai/openai/data-privacy
Transparency Note for Azure OpenAI in Microsoft Foundry Models, Microsoft Learn https://learn.microsoft.com/en-us/azure/foundry/responsible-ai/openai/transparency-note
Compliance in the trusted cloud, Microsoft Azure https://azure.microsoft.com/en-us/explore/trusted-cloud/compliance
Speech-to-Text: AI voice typing and transcription, Google Cloud https://cloud.google.com/speech-to-text
What is Amazon Transcribe?, AWS Documentation https://docs.aws.amazon.com/transcribe/latest/dg/what-is.html
Speech to text with Whisper, Microsoft Foundry, Microsoft Learn https://learn.microsoft.com/en-us/azure/foundry/openai/whisper-quickstart
What is the price for whisper model and what is the quota for normal customer and commitment customer, Microsoft Q&A https://learn.microsoft.com/en-us/answers/questions/1466656/what-is-the-price-for-whisper-model-and-what-is-th